80% concepts. 20% procedure. We measured it.
Why Declarative Knowledge Isn't Enough: The Procedural Gap in AI Agent Skills
We audited 469 AI agent skills and found 80% of the content is declarative knowledge — concepts, definitions, terminology. Only 20% is procedural — the decision trees, failure modes, and quality gates that let agents actually execute. Here's the cognitive science, the data, and the tools to fix it.
You roll out an AI tooling guide to the team. It's well-organized, well-written, has examples. Three weeks later, you watch a junior dev follow it step-by-step and produce something that compiles, passes the tests you wrote, and is quietly wrong in a way only a senior would catch on review. The guide explained what things are. It did not say how to decide what to do when the obvious answer is the wrong one.
That's not a writing problem. It's a category problem. There are two kinds of knowledge in any working manual — declarative ("the API takes a UUID") and procedural ("when the UUID looks like an integer, you've got a billing-vs-tenancy bug; check the dispatch table before the schema"). Most teams write the first kind, because it's easier to write and looks complete on the page.
We audited 469 AI agent skills against a rubric grounded in 70 years of cognitive science research. The numbers came back ugly:
- 54% scored F. Zero scored A.
- The average skill is 80% concepts, 20% procedure.
- The weakest element across the entire library: quality gates — agents literally don't know when they're done.
This isn't a story about lazy writing. It's a structural blind spot in how the entire AI ecosystem builds skills, prompts, and agent instructions — and probably the same shape your team's internal docs have. The blind spot has a name, a theory behind it, and a fix. Here's all three.
The Three Levels of Expert Knowledge
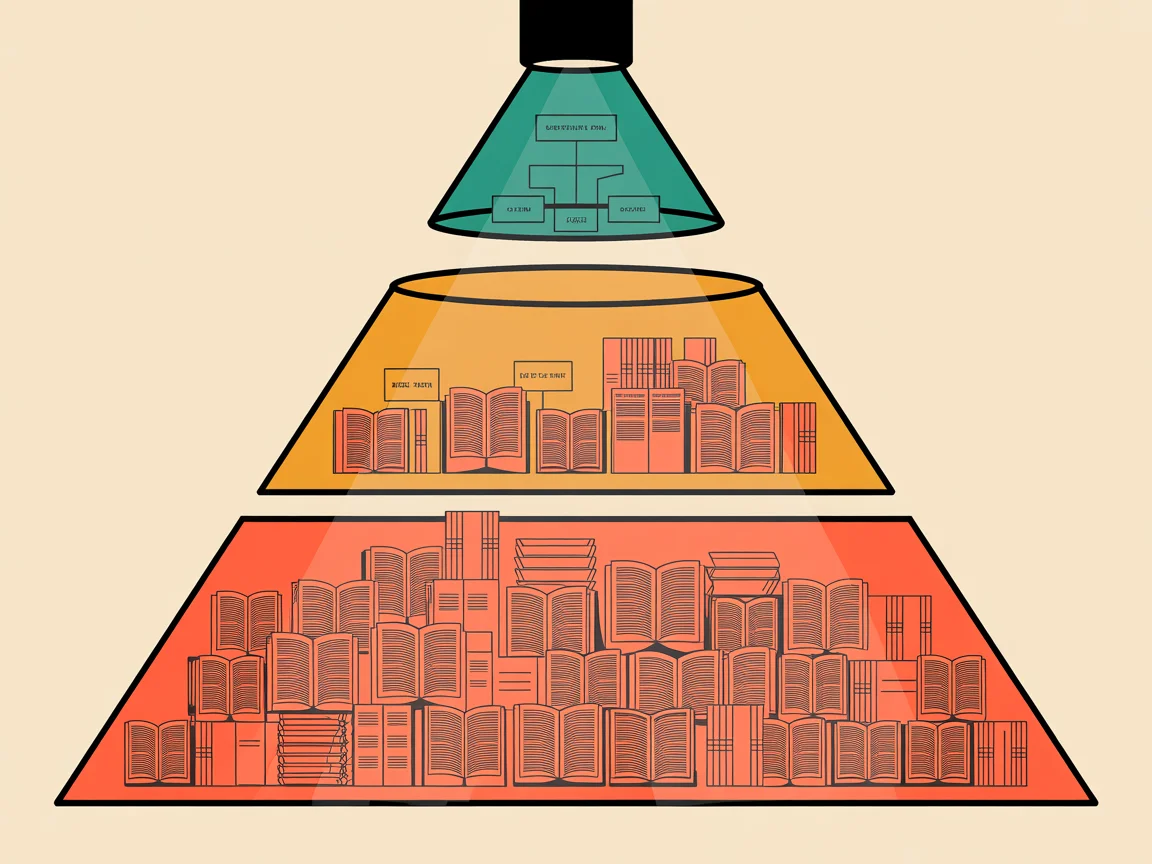
In the 1990s, cognitive scientists Robert Hoffman and Gary Lintern proposed a framework for understanding expert knowledge that's been validated across domains from surgery to firefighting to chess. They described three levels:
Level 1: Domain Constraints — the functional relationships and physical laws that govern a domain. In software engineering, this is "React re-renders when state changes" or "HTTP is stateless." It's the ground truth that doesn't change with perspective.
Level 2: Concepts — categories, terminology, and mental models. "What server components are." "The difference between REST and GraphQL." "What a DAG is." This is textbook knowledge — necessary but not sufficient.
Level 3: Reasoning Strategies — decision heuristics, perceptual cues, and problem-solving logic. "When you see a hydration mismatch, check whether you're reading window in a server component." "If the query asks for a count, use object detection, not CLIP." This is the knowledge that makes experts fast and accurate. It's also the knowledge that's hardest to capture.
Most AI skills are overwhelmingly L2. They describe what things are. They rarely encode how to decide what to do.
This isn't a new problem. Cognitive scientist John Anderson identified it in the 1980s with ACT-R theory: declarative knowledge ("knowing that") is accessible to self-report and explicit instruction. Procedural knowledge ("knowing how") is compiled through practice into fast, unconscious routines that experts can't easily articulate. The more expert someone becomes, the less access they have to the knowledge that makes them expert.
Anderson called this the automation gap. We call it the procedural knowledge problem.
The Report Card: What We Grade On
| Element | Weight | What It Measures |
|---|---|---|
| Decision Points | 30% |
"When you see X, do Y not Z" |
| Failure Modes | 25% |
Symptom → diagnosis → fix |
| Worked Examples | 20% |
Real scenarios with trade-offs |
| Quality Gates | 15% |
"You're done when X is true" |
| NOT-FOR Boundaries | 10% |
Scope limits + delegation |
Each element traces to a specific research tradition — decades of cognitive science about how experts actually think. Here's where they come from.
Where These Ideas Come From
RPD Model
1989 Crandall, Klein
CTA Methods
2006 Imre Lakatos
Proofs & Refutations
1976 George Polya
How to Solve It
1945 Atul Gawande
Checklist Manifesto
2009
Recognition-Primed Decision Making (Gary Klein, 1989)
Klein spent decades studying how experts actually make decisions — not in labs, but on firegrounds, in ICUs, on aircraft carriers. His finding: experts under pressure don't compare options. They recognize the situation as a familiar type, which immediately activates a standard response. The cognitive work isn't "which option is best?" — it's "what is happening here?"
This is why decision points are the highest-weighted element in our rubric. A skill that says "here are 5 API design patterns" is declarative. A skill that says "if you need partial updates, use PATCH; if you need idempotency, use PUT" is procedural — it encodes the recognition step that Klein showed is where expertise actually lives.
Cognitive Task Analysis (Crandall, Klein, Hoffman, 2006)
CTA is the field dedicated to extracting the knowledge that experts can't self-report. The key technique is the Critical Decision Method: you walk an expert through a specific past incident and probe for the decision points they navigated. "What did you notice? What were you expecting? What would a novice have missed?"
The method works because it provides cognitive scaffolding — concrete cases that help experts access compiled procedural knowledge. You can't ask a chess grandmaster "how do you evaluate positions?" and get a useful answer. But you can show them a specific board state and ask "what do you see?" and they'll tell you things a novice literally cannot perceive.
This is the theoretical basis for our upgrade pipeline — a meta-DAG that upgrades skills by running cognitive task analysis on the skills themselves.
Imre Lakatos: Proofs and Refutations (1976)
Lakatos, a philosopher of mathematics, showed that knowledge grows through a dialectic of conjecture and refutation — not through accumulating certified truths. His key concept: monster-barring, where someone encountering a counterexample redefines their terms to exclude it rather than learning from it.
"That's not a real polyhedron" is monster-barring. "That edge case doesn't count" is monster-barring. "Let me add another NOT-FOR clause" is monster-barring.
Our curator system explicitly tracks monster-barring: if a skill responds to failure by narrowing its scope rather than improving its reasoning, that's a degenerating research programme in Lakatos's terms, and the system flags it.
George Polya: How to Solve It (1945)
Polya was a mathematician who studied how people solve problems — not the solutions themselves, but the process of finding them. He identified four phases that every non-trivial problem goes through: Understand the problem, Plan an approach, Execute the plan, and Review what happened.
The insight isn't the phases — it's the failure modes. The most common: jumping from Understanding straight to Execution, skipping Planning entirely. An agent given a task immediately starts writing code instead of first asking "do I know a similar problem? Can I simplify this? What's actually being asked?" This produces technically correct work that answers the wrong question.
The fourth phase — Review — is the one everyone skips. Polya called it "Looking Back" and considered it the most important: after solving, you ask "did this actually work? What assumptions did I make? Could I use this method again?" Without it, every solved problem is an isolated event. With it, each solution teaches you something transferable. This is why worked examples are in our rubric — a skill that includes "here's a real problem I solved, here's how I approached it, here's what I learned" is encoding Polya's fourth phase. A skill that just lists capabilities is stuck in phase one.
Atul Gawande: The Checklist Manifesto (2009)
Gawande showed that even world-class experts — surgeons, pilots — benefit from simple checklists at critical pause points. The checklist doesn't replace expertise; it catches the things experts reliably forget under stress.
His key distinction: DO-CONFIRM checklists (for experts — perform from memory, then verify) vs. READ-DO checklists (for novices — execute each step as read). The power comes from the pause point itself — the moment where execution stops and verification happens.
This is why quality gates are in our rubric: a skill that says "ensure quality" is an aspiration. A skill that says "you're done when all 7 of these conditions are true" is a checklist that catches what agents reliably forget.
The Data: 469 Skills, Graded
| Grade | Count | Percent |
|---|---|---|
| A | 0 | 0% |
| B | 4 | 1% |
| C | 48 | 10% |
| D | 162 | 35% |
| F | 255 | 54% |
Average procedural knowledge score: 57/100. Average procedural content: 20%.
Element-by-element breakdown:
| Element | Avg Score | Present In |
|---|---|---|
| NOT-FOR boundaries | 75.2 | 97% |
| Decision points | 64.3 | 99.8% |
| Failure modes | 54.7 | 88% |
| Worked examples | 45.9 | 64% |
| Quality gates | 45.5 | 57% |
Almost every skill says what it's NOT for (easy to write). Only 57% have quality gates (hard to write — requires knowing what "done" looks like). This is the procedural gap made visible.
What Each Grade Looks Like
0 of 469 skills — the unreached ceiling
Zero out of 469 skills scored above 90. Not one. The best skill in the library — design-justice — scored 84 (a B). So what would an A actually require?
An A-grade skill would need all five elements at high quality and they'd need to reinforce each other. The decision tree would route you to specific failure modes. The failure modes would reference specific worked examples. The worked examples would end by verifying quality gates. The quality gates would include conditions that catch the failure modes. It's a closed loop — each element points at the others.
Concretely, an A-grade api-architect would look something like:
Failure mode includes: "Detection rule: if PATCH handler lacks field-level validation → See Worked Example: Order Status Update"
Worked example walks through the Order Status PATCH, ends with: "Verify against Quality Gate #4: all mutation endpoints validate at field level"
Quality gate #4 catches: "Every PATCH endpoint has field-level validation (prevents the PATCH Without Validation failure mode)"
Each element references the others. The skill is a web, not a list.
None of our skills do this yet. They have decision trees and failure modes and quality gates, but these exist as parallel sections — not as an integrated reasoning structure. Getting from B to A isn't about adding more content. It's about making the content cross-reference itself so an agent navigating one element is naturally led to the others.
That's the next frontier. For now, B is the ceiling and the gap between B (84) and F (54% of the library) is where the leverage is.
design-justice — Score: 84The best skill in the library. Here's why.
Decision tree — not principles, not guidelines, a literal diagnostic flowchart:
├─ YES → Authentication Without Stable Phones
└─ NO → Standard auth OK
User may lose internet mid-task?
├─ YES → Offline-First Design
└─ NO → Standard web patterns OK
This is pure procedural knowledge. It asks a diagnostic question and prescribes the pattern. Most skills skip the diagnosis and just describe the patterns.
Quality gates — testable, binary conditions for "you're done":
Does form data survive connection loss?
Is reading level <= 8th grade?
Can user resume exactly where they left off?
These are Gawande pause points. You're done when all boxes check. Many skills have aspirational principles but no gates for "task complete."
Why B and not A? The working examples could be deeper — more case studies showing trade-offs in real implementations. The failure modes exist but don't include detection rules (the "if you see X, you've violated pattern Y" format that clip-aware-embeddings nails).
clip-aware-embeddings — Score: 84Best failure modes in the library.
This skill has the best failure modes in the library. Each anti-pattern ends with a detection rule:
"How to detect: If query contains 'how many', 'count', or numeric questions -> Use object detection, not CLIP."
This is procedural logic: a testable condition (does the query ask for a count?) that triggers an action (switch to DETR). It's the difference between "here are 5 things CLIP can't do" (declarative) and "here's how to detect in real time that you're about to misuse CLIP" (procedural).
background-job-orchestrator — Score: 79Patterns without diagnosis.
Strong failure modes, strong worked examples, but weaker procedural logic. The skill says "always set up dead letter queues" — that's prescriptive (always do this), not conditional (do this when X). Compare to design-justice's "is the user on a shared device? Yes -> use privacy mode."
C-grade skills give you patterns and anti-patterns, but require you to diagnose which applies. B-grade skills include the diagnosis.
systems-thinking — Score: 60Concepts without procedures.
Conceptually rich, procedurally thin. The anti-patterns are mental mistakes (event-level thinking, parameter obsession), not execution failures (timeout, schema mismatch). No worked examples show how to apply stock-flow analysis to a real problem.
systems-thinkingteaches you how to think (recognize feedback loops, avoid event-level reasoning) — but not how to do things (follow these 7 steps to model a system).
This is the epistemic limit for domains that are primarily conceptual. Some skills should be declarative-heavy — systems-thinking is genuinely about mental models, not procedures. But the audit correctly identifies that an agent can't execute mental models without procedural scaffolding.
research-analyst — Score: 25A job description, not a procedure.
This skill is a job description disguised as expertise:
"Your Mission: Conduct thorough, systematic research to understand landscapes... Core Competencies: Landscape Analysis, Research Methodologies, Information Synthesis."
It says "here's what a research analyst can do" — not "here's how to do research in 7 steps." No decision points, no failure modes, no quality gates. An agent given this skill knows it should do research. It still doesn't know how.
orchestrator — Score: 7A deprecation notice.
A deprecation notice. "Use dag-orchestrator instead." Score of 7 is generous.
See For Yourself: Before & After
Toggle between Before and After to see what the upgrade pipeline does to each skill. Notice the pattern: the upgraded versions are often shorter — declarative concept dumps are verbose, procedural knowledge is information-dense.
The Upgrade Pipeline: How We Fix This
We don't fix 255 F-grade skills by hand. We fix them with a DAG — using the cognitive science that diagnosed the problem.
decision points + failure modes expert-knowledge-elicitation
reasoning from references/
Wave 1 is the key insight. Every skill has a _raw_response.md and references/ folder containing the source material that was compressed into the SKILL.md. That source material likely has procedural reasoning that got lost during compression — the Critical Decision Method in reverse. The cognitive-task-analysis skill re-extracts it.
Wave 3 is the Lakatos check. When the pipeline upgrades a skill, it asks: did we just narrow the skill's scope to avoid hard cases (monster-barring), or did we genuinely incorporate failure into the skill's reasoning (lemma-incorporation)?
Evaluating Skills So They Get Better Over Time

Grading skills once is a snapshot. Making skills get better over time requires a feedback loop.
We built an evaluator hook that runs after every node in a DAG execution. It performs two checks:
Floor check (does the output satisfy the basic contract?) and Wall check (is the output contextually appropriate?). Cost: $0.005 per node. For a 10-node DAG, that's $0.05 of evaluation overhead.
The evaluator's score feeds into Thompson sampling — a Bayesian method for balancing exploration and exploitation. Each successful execution increases the skill's alpha parameter. Each failure increases beta. Over time, skills that work well get selected more often. Skills that fail get explored less — unless they enter a crisis state where the system searches for replacements.
The evaluator explicitly excludes self-assessment from scoring (per Klein's finding that self-evaluation correlates at only 0.749 with actual quality — meaningful but biased). Instead, downstream nodes rate upstream outputs, and the independent evaluator provides a separate signal.
Near-miss detection (from Gawande's safety research): if a skill scores within 10% of the threshold, it's flagged as a near-miss. These are the boundary conditions where the skill is fragile — exactly where Lakatos says the most productive inquiry happens.
The Upgrade: What $12 and 4 Hours Bought

We didn't just measure the gap. We fixed it.
We built a batch upgrade script that feeds each F-grade skill through Sonnet with its audit results and specific gap recommendations. For each skill, Sonnet reads the current SKILL.md, its references, and the audit's per-element scores, then rewrites the skill with decision trees, failure modes, worked examples, and quality gates.
255 F-grade skills. $12.44 in API costs. 4 hours of batch processing. Zero errors.
Then we re-audited a 30-skill sample to measure the change:
| Metric | Before | After | Change |
|---|---|---|---|
| Average Score | 57/100 | 71/100 | +14 points |
| Procedural Content | 20% | 31% | +11pp |
| F-grade | 54% | 17% | -37pp |
| B-grade | 1% | 17% | +16pp |
| C-grade | 10% | 40% | +30pp |
| Weakest element | quality gates | worked examples | Shifted |
The weakest element shifted. Before the upgrade, skills didn't know when they were done (missing quality gates). After, most have quality gates but need richer worked examples. The bottleneck moved upstream — from "I don't know when to stop" to "I need more case studies to pattern-match against." That's progress.
Every upgrade preserved the original in .windags/cta-upgrades/<skill-id>/before.md. The audit that triggered the upgrade is in audit.json. Full provenance, full reversibility.
What The Upgrades Look Like, Qualitatively
national-expungement-expert (F:28 -> B): The before was a flat list of state laws — Clean Slate states, progressive states, restrictive states. Useful as a reference, useless as a procedure. The after has a 4-step eligibility decision tree: offense type check -> state classification -> waiting period calculation -> eligibility path. It also added five named failure modes, including "Guarantee Trap" (symptom: using words like "definitely" -> fix: conditional language) and "Legal Advice Violation" (symptom: telling someone to file papers -> fix: always disclaim). An agent using this skill now navigates a flowchart, not a reference manual.
research-analyst (F:25 -> B): The most dramatic qualitative shift. The before literally read like a job posting: "Core Competencies: Landscape Analysis, Research Methodologies, Information Synthesis." The after classifies every research question by type (factual/comparative/exploratory/causal) and confidence tier (quick check/solid recommendation/high-stakes) before searching. It includes a complete Kafka vs RabbitMQ evaluation walkthrough with source tiering (T1/T2/T3), an evaluation matrix, and a deliberate disconfirming-evidence search. This is the difference between "I'm good at research" and "here's how to research."
dag-performance-profiler (F:19 -> B): Went from 587 lines of TypeScript type definitions (pure declarative — "here's what a trace record looks like") to 175 lines of bottleneck classification trees (procedural — "if latency is 3x average and it's a sequential chain, restructure for parallelization"). The type definitions were describing the system. The decision trees operate it.
What This Means
The procedural knowledge gap isn't specific to WinDAGs. It's universal. Every AI skill, every system prompt, every agent instruction set has the same structural tendency: it's easier to describe what something is than to encode how to decide what to do.
The fix isn't "write better prompts." The fix is to measure the right thing: not whether a skill covers a topic, but whether it encodes the decision points, failure modes, and quality gates that let an agent actually execute with expertise.
And the fix is cheap. A $2.50 Haiku audit tells you where every skill is weak. A $12 Sonnet batch upgrades 255 skills in 4 hours. The cognitive science that powered the rubric is 70 years old. We just needed to apply it.
The full audit data (469 skills, per-element scores, specific recommendations) is available in the WinDAGs repository at .windags/l3-audit/. The before/after artifacts for all 255 upgraded skills are in .windags/cta-upgrades/. The evaluator hook, feedback store, and structural audit system are open source in packages/core/src/. Tools for grading and upgrading your own skills are at curiositech/windags-skills.