Books teach what. People know when. We built tools for both.
The Reasoning Books Don't Have
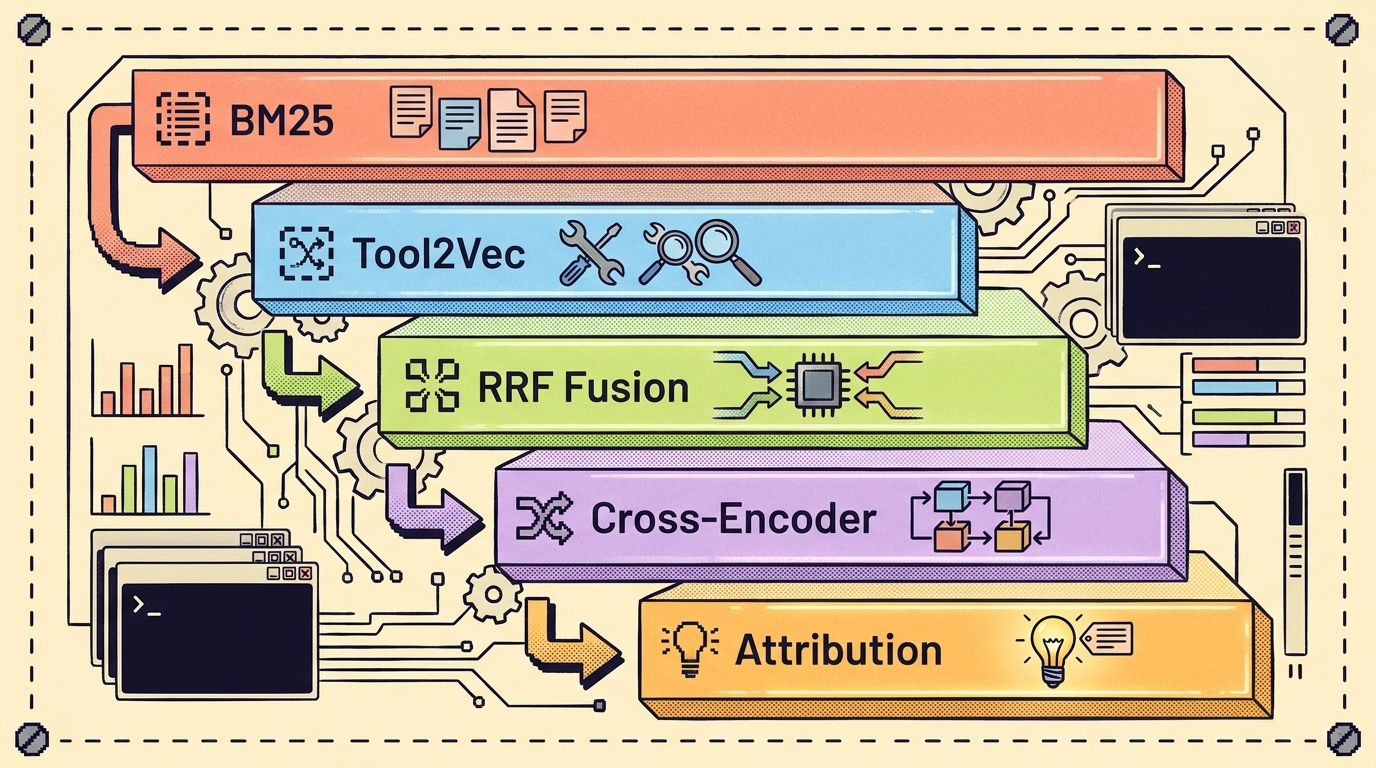
Every team has the senior engineer who 'just knows.' That instinct doesn't fit in a doc — books can't write it, Wikipedia can't index it, and AI doesn't ship with it. We built two tools this weekend: one to pull it out of the people who have it, one to generate it when no one does.
Every engineering team has at least one of these people. The senior who glances at a graph and says "it's not the database, it's head-of-line blocking on the upstream queue." The PM who reads a feature spec in 20 seconds and points at the one constraint everyone missed. The designer who looks at a layout you've stared at for a week and says "the eyeline is wrong."
skillsexpertiseinterviewingbrainstormingknowledge-capture
Read full post