
Less is more — especially when Claude already knows.
WinDAGSZip — Compressing Skills with Embeddings
A 23MB embedding model finds 25% of tokens are self-duplicating in code-heavy skills — for free, no API calls. An LLM judge finds another 20-40% overlaps with training data. We built the tool, measured everything across 10 skills, and shipped it.
It's late. You've been on a long agent session. Your agent took twelve seconds to think before answering an easy question and you watched the spinner. The thing is loaded with skill prompts — 200-line expert documents, dozens of them, every one of them eating context before the model can even read the question. And you start to wonder how much of those tokens is the skill teaching the model something it doesn't know, vs. the skill telling the model things it had already seen a thousand times during pretraining.
We measured it. Across 10 skills totaling 61,408 tokens, 25–46% was redundant — either repeated within the skill (the same example shown three ways) or already absorbed into the model's training data (Stack Overflow's greatest hits). Removing it cost zero measured quality. The compression is free in two senses: free to detect (a 23MB local embedding model does the first pass) and free to apply (the agent gets faster, not worse).
Earlier we audited 469 skills against a 10-axis rubric to make them better. This pass makes them smaller. Same skills, fewer tokens, no quality loss — and a tool you can run on your own catalog.
We built a tool to answer that. It uses a 23MB embedding model to detect intra-skill duplication, an LLM judge to detect pretraining overlap, and rate-distortion theory to find the optimal compression point. We ran it across 10 skills totaling 61,408 tokens. Here's what we found.
The punchline: skills have two kinds of fat, and they need different tools to find. One is free. The other costs about a penny per test case. Together they cut 25-46% of tokens with zero measured quality loss.
The Algorithm

claude plugin install windags-skills
# Then compress any skill:
cd tools/skill-compression
python embed_ablate.py your-skill-name
Now, the deep dive into how it works.
How We Measure "Quality"
Before going further: compression is only useful if quality holds. Here's the eval rubric we use throughout this post.
The Two-Phase LLM Judge
For each (skill variant, test case) pair, we run a two-phase evaluation:
| Phase | Model | Role | Input | Output |
|---|---|---|---|---|
| Executor | Sonnet | Generate a response | Skill text injected via <skill> tag + query from test suite |
A skill-informed response (no tool use allowed) |
| Grader | Haiku | Score the response | Executor's response + expected_behavior from test suite |
{pass, score, evidence} |
The grader is strict. A response that touches on the topic but lacks specific depth from the skill gets a FAIL — generic advice that any AI could produce without the skill doesn't count. This matters because we're testing whether the skill adds value beyond Claude's pretraining, not whether Claude can answer the question at all.
What Defines "Expected Behavior"
Each test case in the eval suite specifies an expected_behavior string written by the skill author. These are the assertions the grader evaluates against. For example:
Query: "What's the similarity threshold I should use for catching duplicates in my skill?"
Expected behavior: "Explains the default 0.70 threshold, recommends lowering to 0.60 for aggressive deduplication with warning about false positives, and suggests validating with graded eval after any threshold change"
The grader must find evidence of each specific claim in the executor's response. Surface-level mentions don't count.
Interpreting Scores
| Metric | Meaning |
|---|---|
| Score (0.0-1.0) | Continuous quality rating per test case |
| Pass/Fail | Binary — did the response meet the expected behavior? |
| Score drop (variant vs baseline) | Quality delta from removing a chunk |
| Score drop < 0.05 | Within measurement noise — safe to compress |
| Score drop > 0.10 | Real quality loss — keep the chunk |
| Negative score drop | Quality improved — the chunk was hurting performance |
Relationship to Anthropic's Skill-Creator Eval
Anthropic's official skill-creator uses a similar architecture: executor generates output, grader agent scores against structured expectations, and an aggregator computes benchmark statistics. The key differences:
| Anthropic skill-creator | Our eval (eval_judge.py) |
|
|---|---|---|
| Grading | Multiple named assertions per case, each pass/fail | Single expected_behavior string, scalar score |
| Comparison | With-skill vs without-skill (or old vs new) | Baseline vs ablated variant |
| Extra features | Blind comparator, benchmark viewer, analyst agent | R-D curve computation, chunk importance ranking |
| Purpose | "Is this skill good?" | "Does removing this chunk change quality?" |
Our eval is a focused subset designed for compression testing. The skill-creator eval answers "is the skill useful?" Our eval answers "is this chunk useful?" Both use the same core insight: an LLM grader judging executor output against human-authored expectations.
Cost
| Component | Cost per test case |
|---|---|
| Executor (sonnet) | ~$0.010 |
| Grader (haiku) | ~$0.001 |
| Total | ~$0.011 |
For windagszip (14 positive test cases, 6 variants): ~$0.92 total. For a full 10-skill audit: ~$60.
Measurement Noise
LLM-as-judge has ±0.15 variance per test case. The same case scored 0.48 in one run and 0.83 in another. Aggregate across 10+ cases for stable signal. Score drops under ±0.05 are noise.
The Problem: Skills Are Expensive Real Estate
Every skill injected into an agent's prompt has three costs: money (input tokens billed per million), attention (the model must parse all of it), and latency (more tokens = slower time-to-first-token). Our skill library ranges from 795 tokens (code-review-checklist) to 14,245 tokens (mcp-creator). When a WinDAGs workflow injects 3-5 skills per agent across 5 waves of parallel execution, token budgets matter.
The question is simple: how much of each skill is actually load-bearing?
Two Types of Fat
We found that skill redundancy comes in two distinct flavors, and they require completely different tools to detect.
Intra-Skill Redundancy
Chunk A says the same thing as chunk B within the same skill. Think of a CSS tutorial that shows position: absolute; inset: 0 in eleven different code blocks — aurora containers, atmosphere layers, fog containers, cloud layers, rain overlays. Each block demonstrates the technique in a slightly different context, but the embedding model sees them as near-identical.
Detection: Embed every chunk with all-MiniLM-L6-v2 (384 dimensions, 23MB ONNX quantized). Compute pairwise cosine similarity. Cluster connected components above 0.70. Within each cluster, keep the canonical version (highest token count) and mark the rest as redundant.
Cost: Zero. The model runs locally. No API calls.
Pretraining Overlap
A chunk teaches something Claude already knows from training data. The PBR shading reference file in metal-shader-expert walks through Physically Based Rendering concepts that Claude learned from thousands of graphics programming resources during training. The reference confirms what Claude knows rather than teaching anything new.
Detection: Remove the chunk and run the LLM-judged eval. If the score doesn't drop, the chunk was pretraining overlap. This requires an executor model (sonnet) to generate a response using the ablated skill, and a grader model (haiku) to score against expected behavior.
Cost: ~$0.011 per test case. About $0.15-0.60 per skill depending on test suite size.
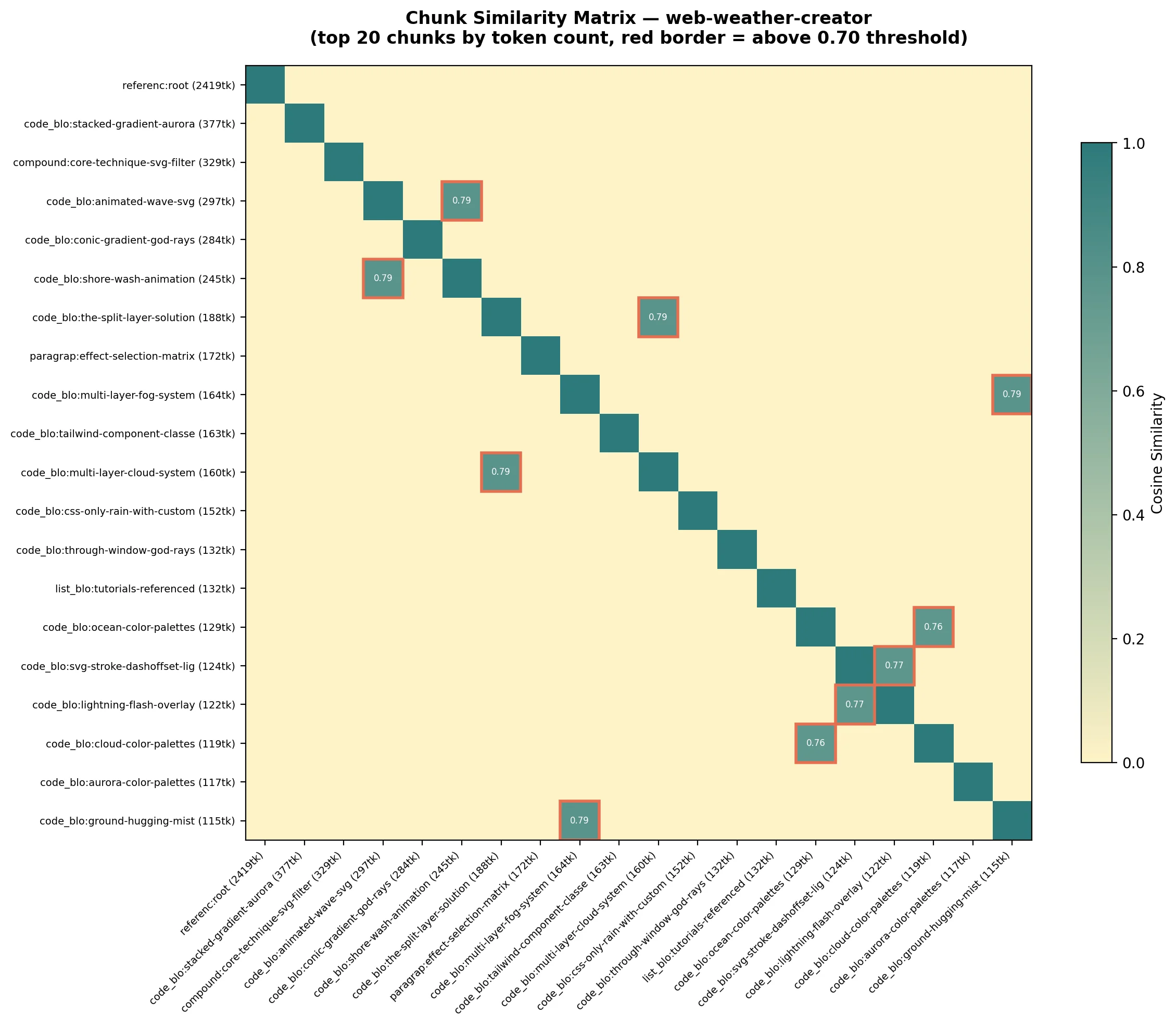
Here's what intra-skill redundancy actually looks like. This is the similarity matrix for web-weather-creator — every red-bordered cell is a pair of chunks saying nearly the same thing.
The diagonal is self-similarity (always 1.0). The off-diagonal red-bordered cells are the interesting ones — chunk pairs that say the same thing. One comprehensive reference file subsumes eleven scattered code examples. The embedding model sees through surface variation to shared semantic structure.
These two types explain a clean bifurcation in the data.
The Embedding Pipeline
Chunking
We reuse the semantic chunker from the quality pass, which identifies 12 chunk types:
| Type | Ablatable | Notes |
|---|---|---|
| FRONTMATTER_FIELD | Some | name/description: never remove |
| SECTION / SUBSECTION | No | Structural anchors |
| COMPOUND | Yes | Paragraph + code block bonded together |
| PARAGRAPH | Yes | Prose content |
| LIST_BLOCK | Yes | Complete list (ablated as unit) |
| CODE_BLOCK | Yes | Code examples |
| REFERENCE | Yes | External reference files (often >1,000 tokens) |
| MERMAID | Yes | Diagram blocks |
Compound units matter: a paragraph that introduces a code block ("Here's how fog works:") must be ablated with its code block. Without this rule, you'd remove the paragraph and orphan the code block — or vice versa.
Similarity Matrix
Every ablatable chunk gets embedded into a 384-dimensional vector. We L2-normalize all embeddings, compute cosine similarity via matrix multiplication, and apply a degenerate-embedding guard (norm < epsilon → skip) to avoid NaN from empty/tiny chunks.
The result is an N×N similarity matrix where each cell is the cosine similarity between two chunks — shown above for web-weather-creator.
Clustering
We build an adjacency graph: edge between chunks when similarity > 0.70. Connected components via BFS. Within each component, the chunk with the highest token count is the canonical version. Everything else is redundant.
Cluster 1 (avg sim: 0.847, redundant tokens: 2,127)
KEEP [reference ] 1821tk Full CSS layering reference...
CUT [code_block ] 312tk .aurora-container { position: absol...
CUT [code_block ] 287tk .atmosphere-layer { position: absol...
CUT [compound ] 198tk Here's how fog works: ...
...
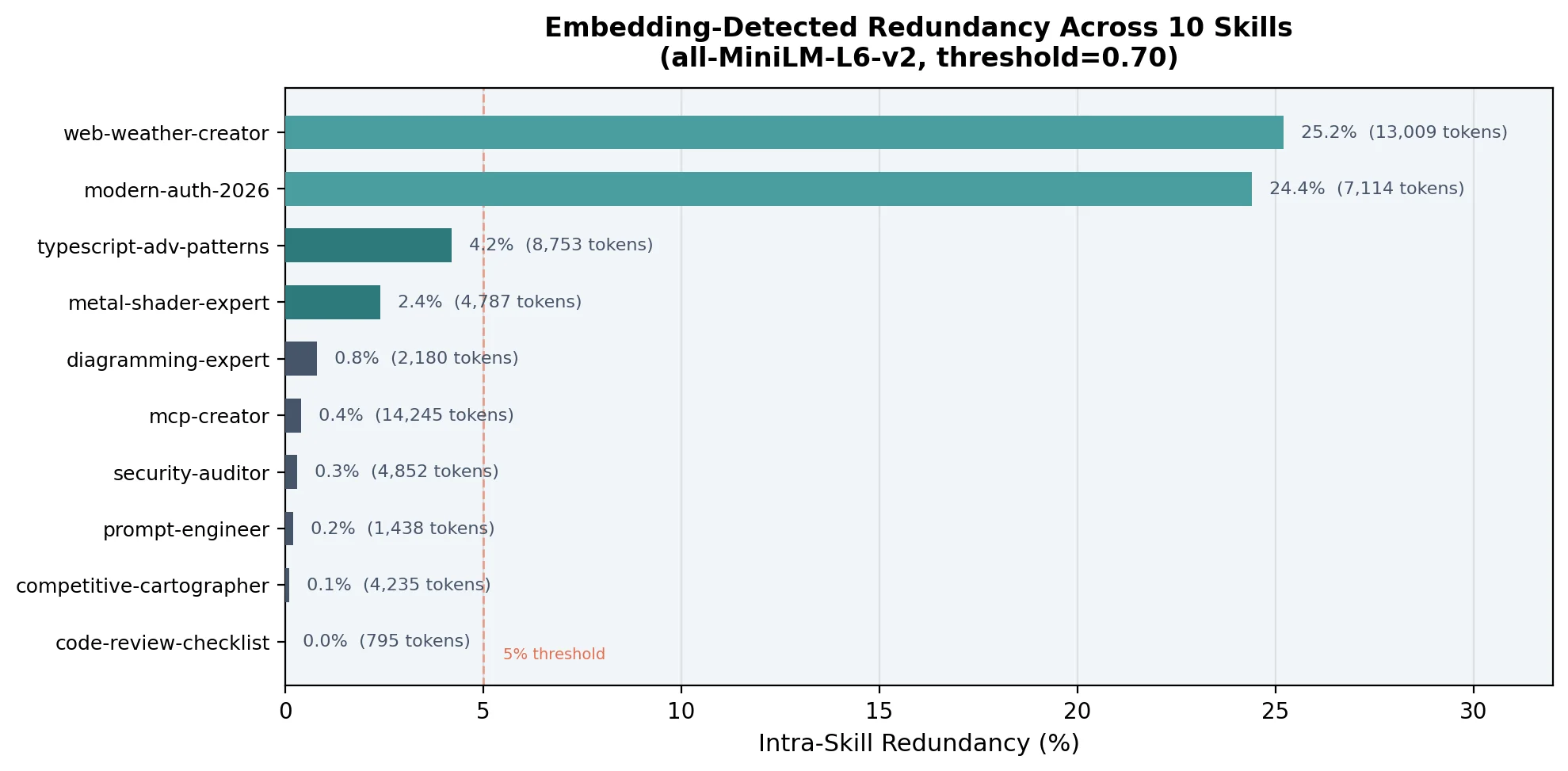
Results Across 10 Skills
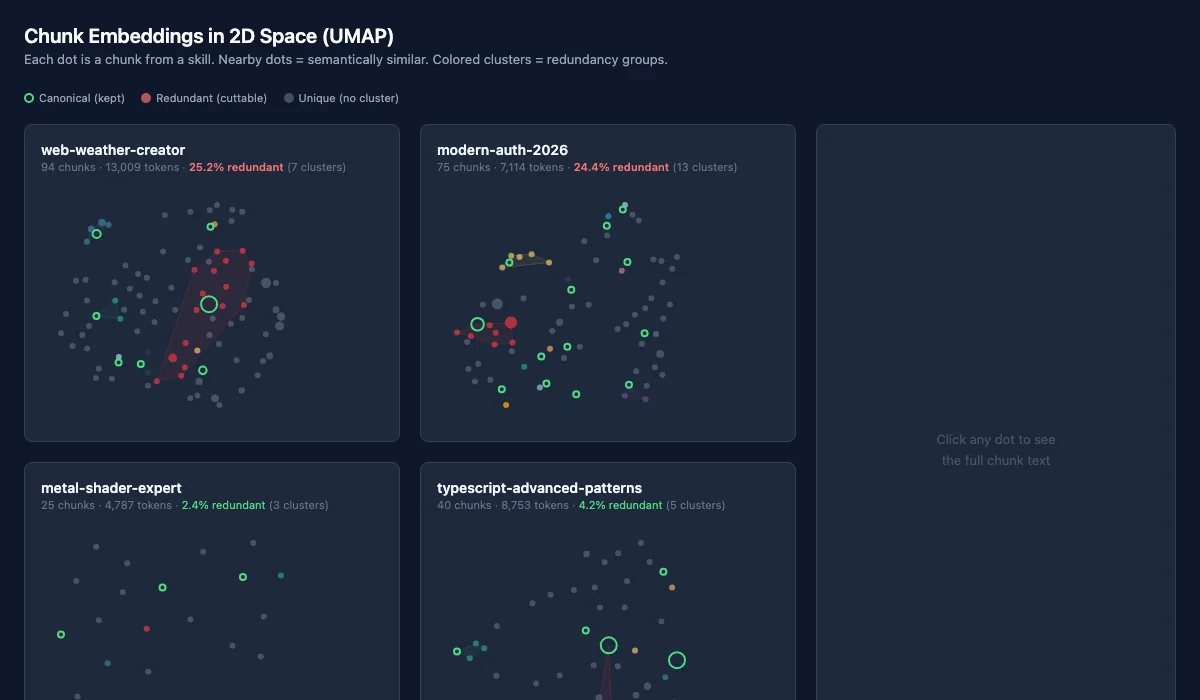
The 10 Specimen Skills
We selected 10 skills spanning both compression regimes — from a 14,245-token MCP construction manual to a 795-token checklist generator. Here's what each one does and what the embeddings found inside.
The data splits cleanly into two regimes:
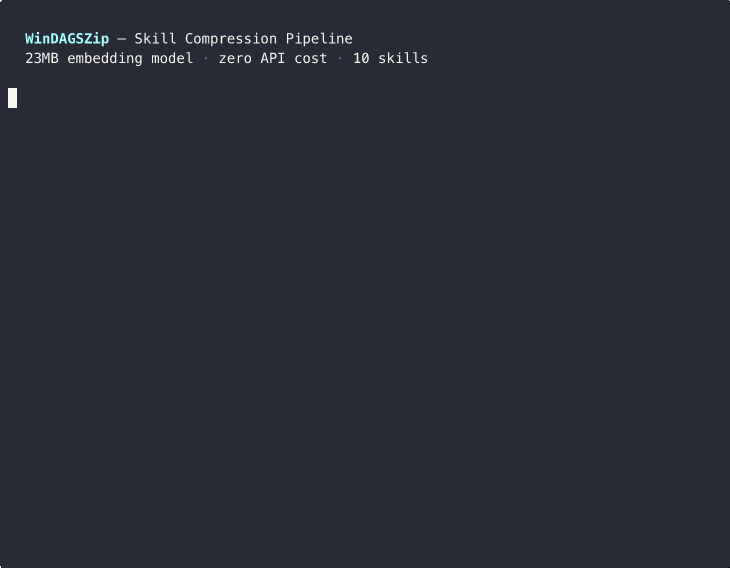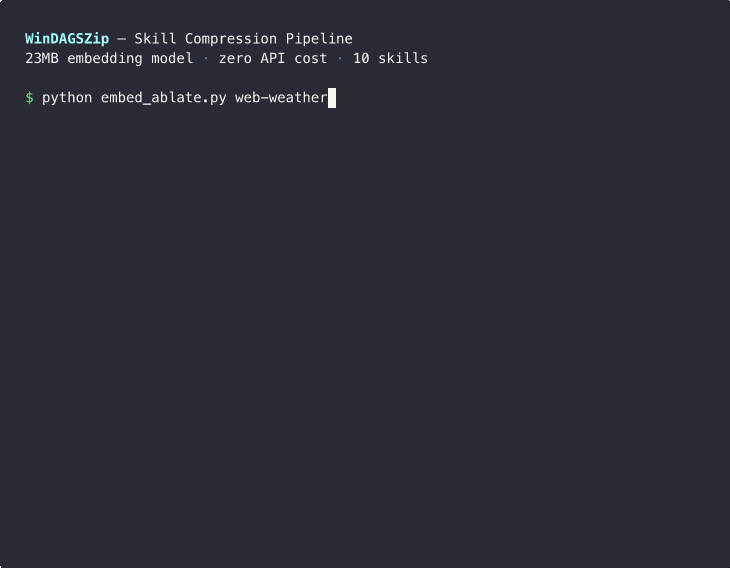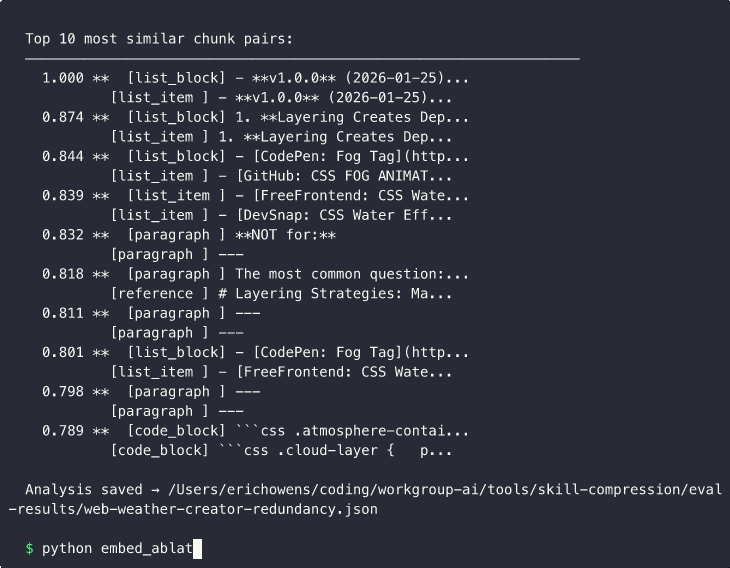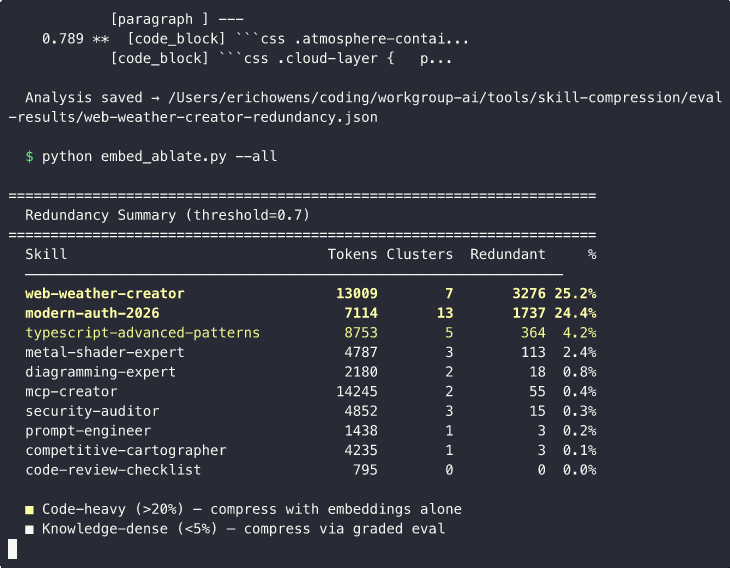
| Skill | Tokens | Clusters | Redundant | % |
|---|---|---|---|---|
| web-weather-creator | 13,009 | 7 | 3,276 | 25.2% |
| modern-auth-2026 | 7,114 | 13 | 1,737 | 24.4% |
| typescript-adv-patterns | 8,753 | 5 | 364 | 4.2% |
| metal-shader-expert | 4,787 | 3 | 113 | 2.4% |
| diagramming-expert | 2,180 | 2 | 18 | 0.8% |
| mcp-creator | 14,245 | 2 | 55 | 0.4% |
| security-auditor | 4,852 | 3 | 15 | 0.3% |
| prompt-engineer | 1,438 | 1 | 3 | 0.2% |
| competitive-cartographer | 4,235 | 1 | 3 | 0.1% |
| code-review-checklist | 795 | 0 | 0 | 0.0% |
Code-heavy skills (web-weather-creator, modern-auth-2026) have 20-25% intra-skill redundancy. These are skills stuffed with code examples showing variations of the same pattern. Compression is free — embeddings alone recover thousands of tokens at zero API cost.
Knowledge-dense skills (the other 8) have less than 5% intra-skill redundancy. Each chunk is distinct from every other chunk within the skill. But the graded eval showed these skills still compress 30-46%. Where does that compression come from? Pretraining overlap. The chunks duplicate what Claude already knows, not what other chunks in the skill already say.
What This Looks Like in Embedding Space
The 2D UMAP projection below shows what redundancy looks like when you flatten 384-dimensional chunk embeddings into two dimensions. Each dot is a chunk from the skill. Nearby dots are semantically similar. Colored clusters are the redundancy groups — within each, the green-ringed dot is the canonical keeper, and the colored dots are cuttable duplicates.
The contrast is immediate. web-weather-creator's plot is dominated by overlapping colored clusters — seven groups of near-identical CSS code. metal-shader-expert is scattered gray dots with barely any clustering. The embedding model sees what the similarity matrix confirmed: code-heavy skills repeat themselves, knowledge-dense skills don't.
web-weather-creator Deep Dive
Seven clusters. 3,276 redundant tokens (25.2%).
The biggest cluster (2,127 tokens) tells a clean story: one reference file on "Layering Strategies" comprehensively covers the CSS positioning pattern. But eleven orphaned code blocks throughout the skill demonstrate the same technique in context — aurora containers, atmosphere layers, fog effects, cloud systems. The embedding model sees them as semantically identical (average similarity: 0.847). The reference file is the canonical version; the eleven blocks are fragments.
Cluster 2 (698 tokens): four SVG filter code blocks (wave, beach, fog, rain) all use <filter> → <feTurbulence> → <feDisplacementMap>. One compound example subsumes the other three.
modern-auth-2026 Deep Dive
Thirteen clusters. 1,737 redundant tokens (24.4%).
The dominant cluster (1,458 tokens) shows seven authentication code blocks all sharing similar patterns with a canonical passkey implementation. The code looks different enough to a human reader — different variable names, different error handling — but the embedding model sees through the surface variation to the shared semantic structure.
The LLM-Judged Pipeline
Embeddings handle intra-skill duplication. But 8 of 10 skills have less than 5% of that. To find pretraining overlap, we need the LLM.
Our initial approach was random ablation — remove one chunk at a time, run the full eval suite, measure the quality delta. This works conceptually but scales terribly: 240 API calls per skill ($1.32), ~28 minutes of wall time, and results within ±0.15 measurement noise. Across 10 skills, that's 2,880 calls, ~$13, and ~24 hours. The semantic embedding pass does the same job for $0 in 20 seconds, so we use it as the first pass and reserve the LLM judge for the targeted second pass — only evaluating chunks that survived embedding dedup.
We built eval_judge.py: a two-phase LLM-judged pipeline.
Phase 1 — Executor: Inject the ablated skill text into a sonnet prompt. Ask the model to demonstrate skill-specific knowledge. The model must answer from the injected skill alone — no tool use allowed.
Phase 2 — Grader: A haiku model evaluates the response against expected behavior assertions. Each assertion gets PASS/FAIL, and the grader produces a continuous 0-1 quality score. The grader is strict: generic advice that any AI could produce without the skill gets a FAIL, even if it's technically correct.
This grader design matters. We're not testing whether Claude can review code (it can). We're testing whether the code-review-checklist skill adds value beyond what Claude already knows. If removing a chunk causes no quality drop, the chunk was either genuinely redundant or covered by training data. Both mean it's safe to remove.
Rate-Distortion Theory
We frame compression as a rate-distortion problem. Rate is tokens consumed in the context window. Distortion is quality drop from compression. The R(D) curve traces the Pareto frontier: minimum tokens for a given quality level. The knee of the curve is the optimal compression point.
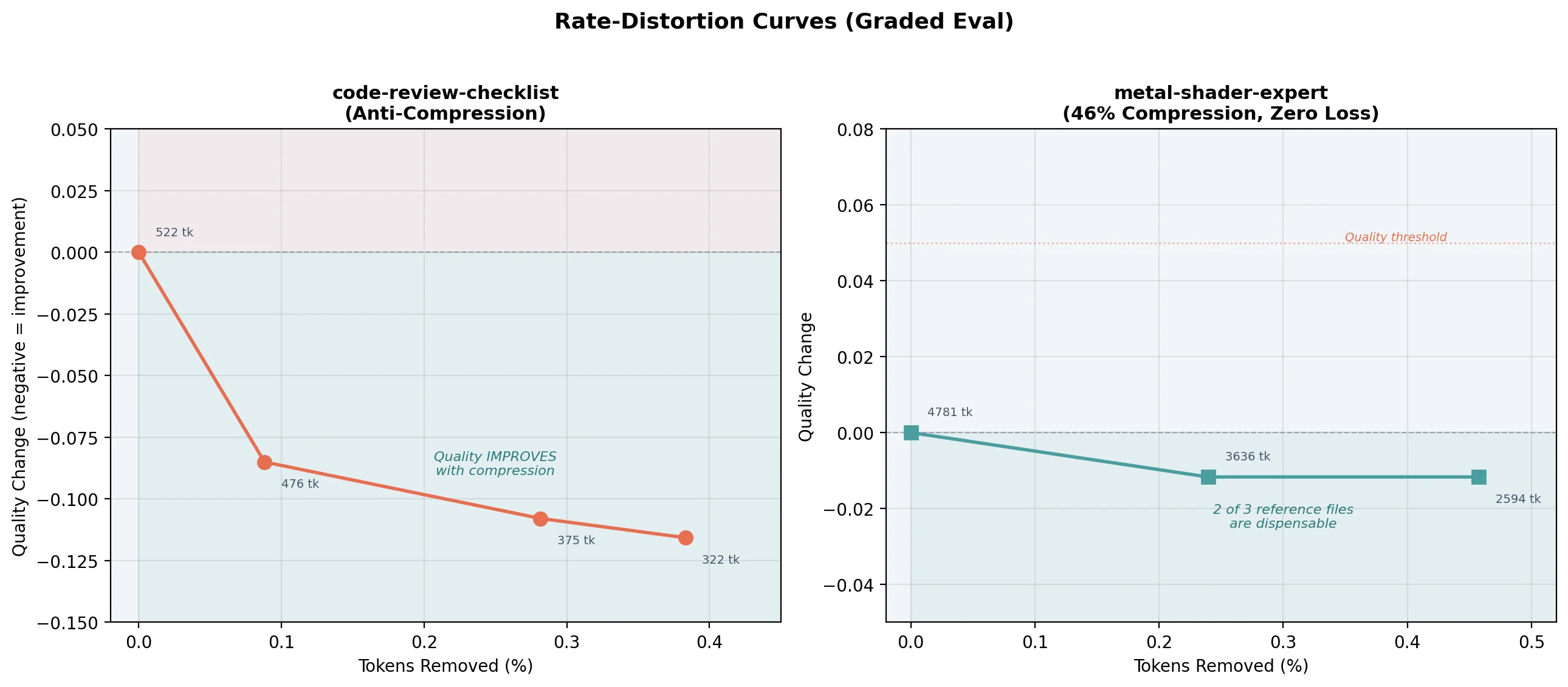
code-review-checklist: The Anti-Compression Finding
| Variant | Tokens | Score | Change |
|---|---|---|---|
| baseline | 522 | 0.646 | — |
| -list_block (46tk) | 476 | 0.731 | +0.085 |
| -list_block (101tk) | 421 | 0.669 | +0.023 |
| -list_block (53tk) | 469 | 0.654 | +0.008 |
Every chunk removal improved quality. The R-D curve goes down — compression reduces distortion.
Why? code-review-checklist is 63 lines about generating code review checklists. Claude already knows how to review code. The skill's list blocks (specific checklist categories) constrain Claude to match those particular items rather than thinking freely. Remove the constraints, and Claude draws from its broader knowledge to produce better reviews.
Implication: Skills about well-known topics should be thin. Their value is in routing ("this user needs a code review checklist"), not content (providing the actual items). Adding detailed content about topics Claude already knows can actively hurt quality.
metal-shader-expert: 46% Compression, Zero Loss
| Variant | Tokens | Score | Change |
|---|---|---|---|
| baseline | 4,781 | 0.860 | — |
| -pbr-shaders.md | 3,636 | 0.872 | -0.012 |
| -noise-effects.md | 3,739 | 0.860 | 0.000 |
| -debug-tools.md | 3,532 | 0.793 | +0.067 |
Two of three reference files are dispensable. The skill compresses from 4,781 to ~2,600 tokens (46%) with zero quality loss. Claude's training data covers PBR shading and noise functions. The references confirm rather than teach.
The real value is in the SKILL.md body: the shibboleths table (half vs float precision, TBDR tile-based deferred rendering, intersector API), the anti-pattern warnings, and the Apple GPU Family 9 specifics. That's ~1,400 tokens of irreducible signal — the stuff Claude doesn't know from training.
windagszip: The Skill That Compresses Itself
The most meta test: running windagszip's own eval pipeline on the windagszip skill itself.
| Chunk Removed | Tokens | Score | Drop | Pass% |
|---|---|---|---|---|
| baseline (full skill) | 2,363 | 0.892 | — | 100% |
| "Step 3: Validate Quality" paragraph + code block | -118 | 0.908 | -0.016 | 100% |
| "Human intuition is unreliable" paragraph | -107 | 0.888 | +0.004 | 100% |
| "Two compression regimes" paragraph + code block | -107 | 0.885 | +0.007 | 93% |
| "More detail always helps" anti-pattern paragraph | -119 | 0.885 | +0.007 | 93% |
| Output contract list (4 items) | -141 | 0.831 | +0.061 | 93% |
The R-D curve tells the compression story:
| Chunks Removed | Tokens | Compression | Distortion |
|---|---|---|---|
| 0 (baseline) | 2,363 | 100% | 0.000 |
| 1 | 2,245 | 95.0% | -0.016 |
| 2 | 2,138 | 90.5% | -0.011 |
| 3 | 2,031 | 86.0% | -0.004 |
| 4 | 1,912 | 80.9% | +0.003 |
Four chunks removed. 451 tokens saved. 19.1% compression. And the cumulative distortion is +0.003 — indistinguishable from noise.
The removed chunks are fascinating:
ablate-016 (quality improved when removed): Instructions on how to run eval_judge.py — the exact tool being used to evaluate it. The executor model doesn't need eval CLI commands to demonstrate compression methodology. The chunk is meta-operational, not content-bearing.
ablate-028, ablate-019, ablate-027 (noise-level drops): Paragraphs explaining why the approach works — "human intuition is unreliable," "two compression regimes," "more detail doesn't always help." These are persuasive prose, not executable knowledge. Claude already knows information theory.
ablate-042 (real quality loss): The output contract — the four-bullet list specifying what windagszip produces (redundancy analysis report, compressed variants, variants manifest, quality evaluation results). This chunk carries the most load because it defines the skill's interface. Without it, the executor produces vague responses that miss concrete deliverables. The grader flags these as fails.
The pattern: Interface definitions and domain-specific details are load-bearing. Explanatory prose about well-known concepts is not. The skill's value isn't in explaining why compression works — it's in specifying what to do and what to produce.
The Two Regimes

Skills fall into two compression regimes:
Code-heavy (>20% intra-skill redundancy): web-weather-creator, modern-auth-2026. These are fat with duplicate code examples. Compress them with embeddings alone — no API costs.
Knowledge-dense (<5% intra-skill): the other 8 skills. Each chunk is unique within the skill, but duplicates Claude's training data. Skip embeddings (there's nothing to find). Go straight to graded eval. The compression savings come from pretraining overlap.
The Optimal Pipeline
Always run embeddings first. The free pass reduces the surface area for the expensive pass. On web-weather-creator, this means graded eval runs on 75% of the original tokens instead of 100% — saving ~25% of API costs for Pass 2.
Packaging as WinDAGSZip
We packaged the pipeline as a distributable skill: skills/windagszip/SKILL.md. A skill about compressing skills — properly meta.
The embedding model ships with WinDAGs as a first-pass compressor. The graded eval is optional — it requires API calls, so it's opt-in for users who want to trace the full R(D) curve.
Running It
# Analyze redundancy (free)
cd tools/skill-compression
python embed_ablate.py web-weather-creator
# Generate compressed variants
python embed_ablate.py web-weather-creator --generate
# Validate quality (costs ~$0.011/case)
python eval_judge.py web-weather-creator \
--variants ablations/web-weather-creator/redundancy-variants.jsonl
Distribution
WinDAGSZip ships alongside next-move and agentic-patterns — three skills in the first wave of public distribution:
- next-move: Analyzes the current project state and recommends what to do next
- agentic-patterns: The five pillars of effective agent behavior (decomposition, orchestration, recovery, context management, quality self-assessment)
- windagszip: Compress any skill with embeddings + optional graded eval
Practical Guidance
When to Compress
- Before deployment: Shrink your skill library before shipping
- After major skill edits: Re-run to catch newly introduced redundancy
- During library audits: The redundancy overview chart is a dashboard for skill health
What the Numbers Mean
| Redundancy | Meaning | Action |
|---|---|---|
| >20% | Heavy self-duplication | Embeddings alone |
| 5-20% | Moderate | Embeddings first, then graded eval |
| <5% | Minimal self-duplication | Skip to graded eval |
| 0% | No intra-skill redundancy | All savings from pretraining overlap |
Quality Thresholds
See the eval rubric at the top of this post for score interpretation, measurement noise, and the relationship to Anthropic's skill-creator evaluation framework.
The 23MB embedding model is sufficient for intra-document comparison. You don't need SOTA. All chunks share topical context (they're from the same skill), so even a small model detects semantic overlap.
What's Next
This post measured redundancy within individual skills. Post 3 looks across the boundary: if two skills produce nearly identical eval vectors on a shared test suite, they're behavioral duplicates regardless of how different their text looks.
The plan:
- Cross-skill deduplication: Build the full behavior matrix (195 skills × N test cases). PCA reveals the natural dimensionality of the skill library. If 195 skills collapse to ~30 principal components, we have massive inter-skill redundancy.
- Skill interpolation: Given related skills A and B, compress as shared_base + delta_A + delta_B. Delta encoding for knowledge.
The tools from this post — the chunker, the embedder, the graded eval — carry forward. The compression pipeline gets more powerful as we move from within-skill to between-skill analysis.
The WinDAGSZip skill and other public skills are available at github.com/curiositech/some_claude_skills. The compression tools are under tools/skill-compression/.